选择二进制纯手工搭建(俗称硬核二进制苦行僧模式),意味着我们将彻底剥离 kubeadm 的黑盒封装,直接与 K8s 的底层内核组件和各种 CA 证书打交道。在这种模式下,我们会对集群的每一颗螺丝钉(组件启动参数、证书签发、网络拓扑)拥有绝对的掌控权。离线环境下,这种方式虽然极为繁琐,但极其稳定,且排查问题直击本质。
安装包清单 我们这里统一采用 Kubernetes v1.28.2,它是一个极度成熟、稳定且完全剥离 Dockershim 的版本,完美兼容 Containerd。你可以任选一台能上网的物理机,将以下组件全部下载并打包运入离线内网。
K8s 核心全家桶组件 K8s 官方将所有二进制组件打包在一个统一的压缩包里。
Etcd 分布式高可用数据库 K8s 集群的唯一物理账本。二进制安装必须单独部署它。
符合 CRI 标准的容器运行时 Containerd + runc + CNI。由于抛弃了 kubeadm,我们需要自己手工组装完全体 CRI 环境。
证书签发重武器 (CFSSL) 二进制安装最大的难关是人肉手签几十张证书(APIserver 证书、Etcd 证书、Kubelet 证书等)。我们需要借用 CFSSL 工具来高效生成。
主机准备和安装规划 主机的基础准备 我们准备了5台机器,全部使用 centos10 最小安装版。下面我们从这个最小安装版出发,构建出我们所需要的5台主机。在每台机器上执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 $ dnf install -y net-tools vim wget lrzsz tar $ sudo hostnamectl set-hostname centos10-06 $ sudo hostnamectl set-hostname centos10-07 $ sudo hostnamectl set-hostname centos10-08 $ sudo hostnamectl set-hostname centos10-09 $ sudo hostnamectl set-hostname centos10-10 $ nmcli connection show $ nmcli connection modify enp0s3 ipv4.addresses 192.168.1.7/24 ipv4.gateway 192.168.1.1 ipv4.dns "114.114.114.114,8.8.8.8" ipv4.method manual $ cat /etc/NetworkManager/system-connections/enp0s3.nmconnection ... $ nmcli connection up enp0s3 $ ip a show enp0s3 $ ip route show $ ping -c 3 192.168.1.6 $ ping -c 3 192.168.1.14 $ vim /etc/hosts 192.168.1.7 centos10-06 192.168.1.6 centos10-07 192.168.1.14 centos10-08 192.168.1.16 centos10-09 192.168.1.17 centos10-10 $ ssh-keygen -t rsa $ ssh-copy-id root@centos10-06 $ ssh-copy-id root@centos10-07 $ ssh-copy-id root@centos10-08 $ ssh-copy-id root@centos10-09 $ ssh-copy-id root@centos10-10
为了简化执行和文件目录的拷贝,我准备了 zshell 脚本。将他们放在每台机器的 zshells-0.0.1 目录下,并为期设置标准的软连接 zshells(解耦),将 zshells 设置在环境变量中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 $ pwd /opt $ ls -la zshells -> /opt/zshells-0.0.1 zshells-0.0.1 $ ls -la zshells-0.0.1 hosts zcall zcopy $ vim zshells-0.0.1/hosts centos10-06 centos10-07 centos10-08 centos10-09 centos10-10 $ vim /etc/profile export ZSHELLS_HOME=/opt/zshellsexport PATH=$ZSHELLS_HOME :$PATH $ source /etc/profile $ zcall ifconfig $ zcopy /opt/zshells-0.0.1 /opt/zshells-0.0.1 $ zcall ln -s /opt/zshells-0.0.1 /opt/zshells $ zcopy /etc/profile $ zcall source /etc/profile
主机的设置 在所有 5 台机器上,用 root 账户无情地砸入以下准备工作,这是奠定集群稳定性的底层基石。
1、彻底关闭 Swap 交换分区(K8s 铁律)。K8s 调度为了极致的性能,默认绝不允许内存数据去挤占慢速的磁盘 Swap。
1 2 3 4 swapoff -a && sysctl -w vm.swappiness=0 sed -i '/swap/s/^/#/' /etc/fstab
2、彻底关闭 SELinux 与防火墙。为了防止 CentOS 10 严苛的安全策略误杀 K8s 内部复杂的隧道网络:
1 2 3 4 5 6 7 systemctl stop firewalld systemctl disable firewalld setenforce 0 sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
3、安装 Chrony 时间同步服务。注意 Chrony 守护进程本身就是“渐进式微调”的高手,很多老运维习惯在 crontab 里写一句 “/5 * /usr/sbin/ntpdate ntp.aliyun.com”,但建议千万别这么干,因为致命的 “时间跳变” 会瞬间搞崩 Etcd。如果时间突然往前跳或者往后大跨步,Etcd 会误以为心跳超时,从而疯狂触发 Leader 重新选举,直接导致你的 K8s 脑裂、集群瞬间瘫痪。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 dnf install -y chrony vim /etc/chrony.conf server ntp.aliyun.com iburst server time1.cloud.tencent.com iburst server time.windows.com iburst systemctl enable --now chronyd chronyc hwtimestamp * chronyc tracking hwclock --systohc chronyc sources -v chronyc sourcestats -v
4、更改文件描述符上线(一般改成 65535 以上)
nofile (Number of Open Files):单进程允许打开的最大文件句柄数。直接从 1024 暴力拔高到 65536,Java 微服务和高并发网络从此彻底解套。
nproc (Number of Processes):单个用户允许创建的最大进程/线程数。防止高并发下 Netty 或 Tomcat 线程池发生“线程风暴”时被 Linux 强行锁喉。
limits.conf 的修改不需要你重启整台 CentOS 10 虚拟机,它对新建立的会话(SSH 连接)会当场生效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vim /etc/security/limits.conf * soft nofile 65536 * hard nofile 65536 * soft nproc 65535 * hard nproc 65535 root soft nofile 65536 root hard nofile 65536 root soft nproc 65535 root hard nproc 65535 ulimit -nulimit -u
5、打开 Linux 桥接网络隧道(CRI 容器互通的物理大门)
让 Linux 的 IPv4 流量能够平滑穿透网桥,这是 Pod 之间能隔空通信的硬核前提。在物理宿主机的世界里,每台机器只有一张真正的物理网卡(比如 192.168.1.7)。但是 K8s 降临后,要在机器里凭空孵化出成百上千个 Pod,每个 Pod 都有一个独立的虚拟 IP(比如 10.244.x.x)。这就会带来两个物理矛盾:
流量穿透问题:Pod 们的虚拟 IP 都在一个虚拟的“网桥(Bridge)下面活动。当一个 Pod 想把数据包发给另一个 Pod 时,Linux 系统默认是个保守的看门人,它一瞅这不是物理网卡进来的正经流量,而是网桥内部流转的黑户流量,于是默认会把这些数据包拦截并扔掉。modprobe overlay/br_netfilter 就像是下达了特赦令,强行在 Linux 内核里修了一条高架桥(网桥过滤驱动),让网桥流量能够畅通无阻地穿透出去。
绕过安检问题:K8s 的网络大坝(如 kube-proxy)是用系统的 iptables(防火墙黑账本)来做流量转发的(比如把访问大盘 Service 的流量导向真正的 Pod)。net.bridge.bridge-nf-call-iptables = 1 这三行内核参数,就是告诉 Linux 内核:只要网桥里有流量走过,必须立刻通知 iptables 黑账本进行安检和地址翻译。如果不加这一行,流量在网桥里瞎转悠,根本找不到 K8s 的转发规则,直接迷路。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ cat <<EOF | tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF modprobe overlay modprobe br_netfilter cat <<EOF | tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 EOF $ sysctl --system
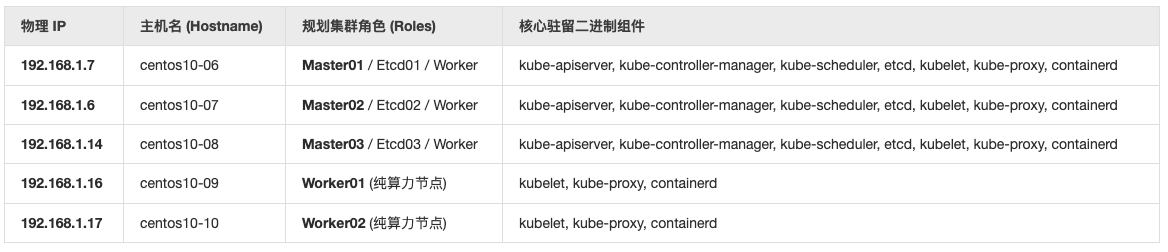
安装规划 集群拓扑规划 在分布式架构中,最稳健的比例是 3台 Master(确保大脑 Etcd 选举的奇数安全法则是 $3=2\times1+1$)+ 2台纯 Worker。同时,为了榨干所有机器的算力,我们将 Master 节点也打上“可调度” 标签,让它们在日常情况下也能分担 Pod 容器的运行。下面是角色分配对照表:
为什么这样规避高可用死锁?
Etcd 奇数活体定理 :Etcd 采用了 Raft 强一致性算法。3 台 Etcd 允许挂掉 1 台(仍有 2 台存活过半数),这意味着如果 centos10-06 物理断电,大盘、API网关和集群调度绝不崩盘。Kube-VIP 或 Nginx 代理网关 :因为我们有 3 台 Apiserver,Worker 节点绝不能死死指向某一台的 IP!我们后续必须在 3 台 Master 上配置一个虚拟 IP(VIP,比如 192.168.1.200)或者在 Worker 上用本地 nginx/haproxy 进行四层负载均衡。
网络与子网规划 二进制安装中,网络范围(CIDR)一旦在启动参数里写死,后期修改就是灾难。我们需要严密规划好这三张网的物理边界。Service 网段 (Cluster-IP CIDR) 设定为 10.96.0.0/16,K8s 内部网关 DNS 预留 IP 焊死在 10.96.0.10(CoreDNS 使用)。Pod 网段 (Cluster-Pod CIDR) 设定为 10.244.0.0/16,K8s 会自动为 5 台机器切分小蛋糕,比如 centos10-06 分到 10.244.0.0/24,centos10-07 分到 10.244.1.0/24,物理隔离互不干扰。
1 2 3 4 5 【物理宿主机网段】 192.168.1.0/24 --> 5 台 CentOS 机器 IP │ ├───【Service 虚拟网段】 10.96.0.0/16 --> K8s 内部 VIP 网段(如 Dashboard、CoreDNS IP) │ └───【Pod 容器虚拟网段】 10.244.0.0/16 --> Flannel/Calico 分配给每个 Pod 的专属网段。
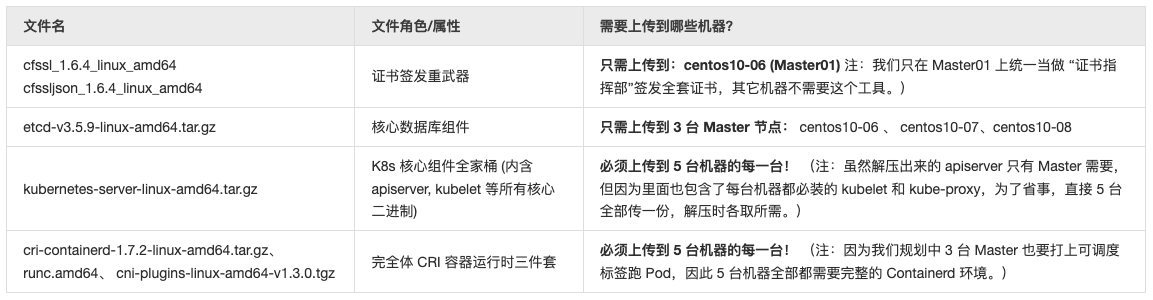
文件分发对照表
正式安装 手动签发全套集群证书 在二进制手工搭建中,整个 K8s 集群的核心安全根基就是 CA 证书 。无论是 apiserver 通信、etcd 账本多活、还是 kubectl 鉴权,都必须拿着盖有同一个根证书大印的通行证。我们选择 centos10-06 (Master01) 作为唯一的指挥部,在这里生成所有证书,然后再隔空分发给兄弟节点。
步骤 1.1:武装证书签发重武器 (CFSSL)。
我们需要把 cfssl 二进制文件移入系统生存库,并赋予它们物理执行特权。在 centos10-06 终端运行:
1 2 3 4 5 6 7 8 9 mv cfssl_1.6.4_linux_amd64 /usr/local/bin/cfsslmv cfssljson_1.6.4_linux_amd64 /usr/local/bin/cfssljsonchmod +x /usr/local/bin/cfssl /usr/local/bin/cfssljsoncfssl version
步骤 1.2:创建全局统一证书作坊目录
为了绝不和其它文件混淆,我们专门开辟一个干净的作坊目录:
1 mkdir -p /k8s/v1.28.2/work && cd /k8s/v1.28.2/work
步骤 1.3:锻造根证书大印 (CA Root)
根证书(CA)是整个集群的最高信仰,其它所有证书都是由它衍生、签发出来的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 $ cat <<EOF | tee ca-config.json { "signing": { "default": { "expiry": "876000h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "876000h" } } } } EOF $ cat <<EOF | tee ca-csr.json { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "O": "k8s", "OU": "system" } ], "ca": { "expiry": "876000h" } } EOF $ cfssl gencert -initca ca-csr.json | cfssljson -bare ca $ ls ca-config.json ca-csr.json ca.csr ca-key.pem ca.pem
步骤 1.4:为 Etcd 数据库账本签署高可用通行证
Etcd 是高可用集群的底层数据库,3 台 Master(06、07、08)之间互相同步数据必须使用 HTTPS 加密,且必须在证书里锁死这 3 台机器的物理 IP。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 $ cat <<EOF | tee etcd-csr.json { "CN": "etcd", "hosts": [ "127.0.0.1", "192.168.1.7", "192.168.1.6", "192.168.1.14" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "O": "k8s", "OU": "system" } ] } EOF $ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes etcd-csr.json | cfssljson -bare etcd $ ls ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem etcd.csr etcd-csr.json etcd-key.pem etcd.pem
步骤 1.5:为集群大脑 Kube-Apiserver 签署顶级网关证书
kube-apiserver 是集群最核心的流量入网通道。不仅 5 台宿主机要访问它,集群内部的 Pod、Service VIP、甚至我们未来的大盘都要访问它。所以这里的 IP 锁死极为严格,错一个字就会导致 K8s 内部不认账。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 $ cat <<EOF | tee kubernetes-csr.json { "CN": "kubernetes", "hosts": [ "127.0.0.1", "10.96.0.1", "192.168.1.7", "192.168.1.6", "192.168.1.14", "192.168.1.16", "192.168.1.17", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "O": "k8s", "OU": "system" } ] } EOF $ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kubernetes-csr.json | cfssljson -bare kubernetes $ ls ca-config.json ca-csr.json ca.pem etcd-csr.json etcd.pem kubernetes-csr.json kubernetes.pem ca.csr ca-key.pem etcd.csr etcd-key.pem kubernetes.csr kubernetes-key.pem
步骤 1.6:签署管理员(最高特权)证书
由于客户端命令行工具 kubectl 以及各种超级组件(比如控制中心、大盘)需要对 K8s 具有最高管辖权,我们为其单独签发一份具备 system:masters 超级管理员用户组大印的证书。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 $ cat <<EOF | tee admin-csr.json { "CN": "admin", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "O": "system:masters", "OU": "system" } ] } EOF $ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin $ ls admin.csr admin-key.pem ca-config.json ca-csr.json ca.pem etcd-csr.json etcd.pem kubernetes-csr.json kubernetes.pem admin-csr.json admin.pem ca.csr ca-key.pem etcd.csr etcd-key.pem kubernetes.csr kubernetes-key.pem
步骤 1.7:签署集群网络代理(Kube-Proxy)通行证
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ cat <<EOF | tee kube-proxy-csr.json { "CN": "system:kube-proxy", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "O": "k8s", "OU": "system" } ] } EOF $ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy $ ls admin.csr admin.pem ca-csr.json etcd.csr etcd.pem kube-proxy-key.pem kubernetes-csr.json admin-csr.json ca-config.json ca-key.pem etcd-csr.json kube-proxy.csr kube-proxy.pem kubernetes-key.pem admin-key.pem ca.csr ca.pem etcd-key.pem kube-proxy-csr.json kubernetes.csr kubernetes.pem
至此,在 centos10-06 的 /k8s/v1.28.2/work 目录下,我们一共用纯手工创建了全套集群核心骨骼证书!现在可以通过输入 “ls *.pem” 严密盘查:
ca.pem / ca-key.pem (最高根印章)
etcd.pem / etcd-key.pem (Etcd 专用)
kubernetes.pem / kubernetes-key.pem (Apiserver 专用)
admin.pem / admin-key.pem (最高管理员凭证)
kube-proxy.pem / kube-proxy-key.pem (网络代理凭证)
接下来我们将进入第二步,利用刚刚签出的 etcd.pem 证书,在 3 台 Master 机器上同时组装并拉起 Etcd 分布式高可用账本。
安装 Master Etcd Etcd 数据库采用了 Raft 协议,3 台 Etcd 必须同时启动、彼此对齐暗号、完成选主(Leader Election),账本才算真正通电激活。由于此时所有证书都在 centos10-06 (Master01) 上,我们需要分三步走:分发物料 → 编写启动参数 → 三台同时合闸启动 。
步骤 2.1:跨机器隔空投送证书与二进制包分发
1 2 3 4 5 6 7 scp etcd-v3.5.9-linux-amd64.tar.gz root@centos10-07:/root/ scp ca.pem etcd.pem etcd-key.pem root@centos10-07:/root/ scp etcd-v3.5.9-linux-amd64.tar.gz root@centos10-08:/root/ scp ca.pem etcd.pem etcd-key.pem root@centos10-08:/root/
步骤 2.2:三台 Master 无差别就地解压、归位(三台 Master 同时进行)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 mkdir -p /k8s/kubernetes/binmkdir -p /k8s/kubernetes/cfg/sslcd /root/tar -xf etcd-v3.5.9-linux-amd64.tar.gz cp etcd-v3.5.9-linux-amd64/etcd* /k8s/kubernetes/bin/cp /k8s/v1.28.2/work/ca.pem /k8s/v1.28.2/work/etcd.pem /k8s/v1.28.2/work/etcd-key.pem /k8s/kubernetes/cfg/ssl/scp -r /k8s/kubernetes/cfg/ssl root@centos10-07:/k8s/kubernetes/cfg scp -r /k8s/kubernetes/cfg/ssl root@centos10-08:/k8s/kubernetes/cfg echo 'export PATH=$PATH:/k8s/kubernetes/bin' >> /etc/profilesource /etc/profile
步骤 2.3:对号入座,手写各自的 Etcd 启动黑账本(各自独立执行!)
由于 Etcd 需要严格分清自己是谁、别人是谁,这一步绝不能同步执行,必须各自单独在各自的机器上手工编写配置文件。
在 centos10-06 (192.168.1.7) 上创建核心配置文件,其中:
2380 端口:集群内部各成员手拉手对暗号、同步账本的物理私密通道。
2379 端口:未来 K8s 集群大脑(Apiserver)过来存取数据的公开柜台。
无论在哪台机器,最后的 ETCD_INITIAL_CLUSTER 必须全量包含 3 台机器的集群视图!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cat <<EOF | tee /k8s/kubernetes/cfg/etcd.conf #[Member] ETCD_NAME="etcd-01" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.1.7:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.1.7:2379" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.7:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.7:2379" ETCD_INITIAL_CLUSTER="etcd-01=https://192.168.1.7:2380,etcd-02=https://192.168.1.6:2380,etcd-03=https://192.168.1.14:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-k8s-cluster" ETCD_INITIAL_CLUSTER_STATE="new" EOF
在 centos10-07 (192.168.1.6) 上创建核心配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cat <<EOF | tee /k8s/kubernetes/cfg/etcd.conf #[Member] ETCD_NAME="etcd-02" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.1.6:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.1.6:2379" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.6:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.6:2379" ETCD_INITIAL_CLUSTER="etcd-01=https://192.168.1.7:2380,etcd-02=https://192.168.1.6:2380,etcd-03=https://192.168.1.14:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-k8s-cluster" ETCD_INITIAL_CLUSTER_STATE="new" EOF
在 centos10-08 (192.168.1.14) 上创建核心配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cat <<EOF | tee /k8s/kubernetes/cfg/etcd.conf #[Member] ETCD_NAME="etcd-03" ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="https://192.168.1.14:2380" ETCD_LISTEN_CLIENT_URLS="https://192.168.1.14:2379" #[Clustering] ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.1.14:2380" ETCD_ADVERTISE_CLIENT_URLS="https://192.168.1.14:2379" ETCD_INITIAL_CLUSTER="etcd-01=https://192.168.1.7:2380,etcd-02=https://192.168.1.6:2380,etcd-03=https://192.168.1.14:2380" ETCD_INITIAL_CLUSTER_TOKEN="etcd-k8s-cluster" ETCD_INITIAL_CLUSTER_STATE="new" EOF
步骤 2.4:编写 Systemd 系统托管卡片(开启多窗口同步流)
我们需要向 CentOS 系统的最底层注册托管服务。重新打开 3 台 Master 的同步窗口,同时运行以下命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 cat <<EOF | tee /usr/lib/systemd/system/etcd.service [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target [Service] Type=notify EnvironmentFile=/k8s/kubernetes/cfg/etcd.conf ExecStart=/k8s/kubernetes/bin/etcd \\ --cert-file=/k8s/kubernetes/cfg/ssl/etcd.pem \\ --key-file=/k8s/kubernetes/cfg/ssl/etcd-key.pem \\ --trusted-ca-file=/k8s/kubernetes/cfg/ssl/ca.pem \\ --peer-cert-file=/k8s/kubernetes/cfg/ssl/etcd.pem \\ --peer-key-file=/k8s/kubernetes/cfg/ssl/etcd-key.pem \\ --peer-trusted-ca-file=/k8s/kubernetes/cfg/ssl/ca.pem \\ --peer-client-cert-auth \\ --client-cert-auth Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF
步骤 2.5:全盘起爆!由于 Raft 机制的死锁限制,当你启动第一台(比如 06)时,终端会卡住不动甚至报错,这非常正常!因为第一台在疯狂呼唤另外两台兄弟上线。最畅快的正确姿势是,保持 3 台 Master 的同步窗口开启,直接在同步终端里一脚砸入启动命令,逼迫 3 台机器在 1 秒钟内同时通电并网!
1 2 3 4 5 6 7 8 systemctl daemon-reload systemctl start etcd systemctl enable etcd
步骤 2.6:验证是否启动成功。Etcd 究竟组装成功没有?我们直接在任意一台 Master 节点(比如 centos10-06)上,拿着最高根证书去它的物理账本前盘查对账。只要看到三行大写的 true,说明分布式高可用底层数据库账本彻底通电。
1 2 3 4 5 6 7 8 9 10 11 12 13 $ etcdctl --cacert=/k8s/kubernetes/cfg/ssl/ca.pem \ --cert=/k8s/kubernetes/cfg/ssl/etcd.pem \ --key=/k8s/kubernetes/cfg/ssl/etcd-key.pem \ --endpoints="https://192.168.1.7:2379,https://192.168.1.6:2379,https://192.168.1.14:2379" \ endpoint health --write-out=table +---------------------------+--------+------------+-------+ | ENDPOINT | HEALTH | TOOK | ERROR | +---------------------------+--------+------------+-------+ | https://192.168.1.7:2379 | true | 32.0848ms | | | https://192.168.1.6:2379 | true | 49.49819ms | | | https://192.168.1.14:2379 | true | 50.47643ms | | +---------------------------+--------+------------+-------+
安装 Master kube-X kube-apiserver(统一网关)、kube-controller-manager(核心控制中心)和 kube-scheduler(分布式调度器)共同构成了 Kubernetes 的最高指挥系统。为了让 3 台 Master 的 API 网关处于完美对称的多活状态,绝对不能让 Worker 节点和管理工具绑死在某一台具体的 Master IP 上。我们将分四个阶段合拢网关:生成高可用 VIP → 解压归位全家桶 → 签发内部通行证 → 编写黑账本并全量起爆 。
步骤 3.1:修筑 HAProxy 高可用四层防线(3台 Master 同步流)。
HAProxy 是专为负载均衡而生的。Nginx 核心是 HTTP 服务器,其四层转发(stream 模块)属于后期加入的插件;而 HAProxy 原生就是高性能反向代理,对底层 TCP 长连接、保持心跳、重试机制的控制要比 Nginx 精准和轻量得多。
开启 3 台 Master(06、07、08)的同步输入窗口,统一安装并配置 HAProxy。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 $ yum install -y haproxy $ cat <<EOF | tee /etc/haproxy/haproxy.cfg global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon defaults mode tcp log global retries 3 timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout check 10s maxconn 3000 # 核心并网入闸口:监听本地 16443 端口,隔空轰击 3 台 Master 的真实 6443 接口 frontend k8s-apiserver bind 127.0.0.1:16443 mode tcp default_backend k8s-masters # 后端三星大阵高可用健康检查 backend k8s-masters mode tcp balance roundrobin server centos10-06 192.168.1.7:6443 check inter 2000 fall 3 rise 2 server centos10-07 192.168.1.6:6443 check inter 2000 fall 3 rise 2 server centos10-08 192.168.1.14:6443 check inter 2000 fall 3 rise 2 EOF $ sysctl -w net.ipv4.ip_nonlocal_bind=1 $ echo "net.ipv4.ip_nonlocal_bind = 1" >> /etc/sysctl.d/k8s.conf $ sysctl --system $ systemctl daemon-reload && systemctl start haproxy && systemctl enable haproxy $ netstat -lntp | grep 16443
阶段 3.2:全家桶解压归位(回到 centos10-06 建立指挥部)
请切回到 centos10-06 (Master01) 终端上,将解压出来的核心二进制与公钥分发投送给兄弟们:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ tar -xf /root/kubernetes-server-linux-amd64.tar.gz $ cp /root/kubernetes/server/bin/kube-apiserver /k8s/kubernetes/bin/ $ cp /root/kubernetes/server/bin/kube-controller-manager /k8s/kubernetes/bin/ $ cp /root/kubernetes/server/bin/kube-scheduler /k8s/kubernetes/bin/ $ cp /root/kubernetes/server/bin/kubectl /k8s/kubernetes/bin/ $ cd /k8s/v1.28.2/work $ cp ca.pem ca-key.pem kubernetes.pem kubernetes-key.pem admin.pem admin-key.pem kube-proxy.pem kube-proxy-key.pem /k8s/kubernetes/cfg/ssl/ $ scp /k8s/kubernetes/bin/kube-apiserver /k8s/kubernetes/bin/kube-controller-manager /k8s/kubernetes/bin/kube-scheduler /k8s/kubernetes/bin/kubectl root@centos10-07:/k8s/kubernetes/bin/ $ scp /k8s/kubernetes/bin/kube-apiserver /k8s/kubernetes/bin/kube-controller-manager /k8s/kubernetes/bin/kube-scheduler /k8s/kubernetes/bin/kubectl root@centos10-08:/k8s/kubernetes/bin/ $ scp /k8s/kubernetes/cfg/ssl/*.pem root@centos10-07:/k8s/kubernetes/cfg/ssl/ $ scp /k8s/kubernetes/cfg/ssl/*.pem root@centos10-08:/k8s/kubernetes/cfg/ssl/
阶段 3.3:手写 Kubeconfig 鉴权加密公文包(在 centos10-06 上执行)。因为我们用 HAProxy 接管了网关,所有的 server 地址完美绑定在本地负载均衡端口 https://127.0.0.1:16443 上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 $ cd /k8s/v1.28.2/work $ mkdir -p /k8s/kubernetes/cfg/kubeconfig $ kubectl config set-cluster kubernetes --certificate-authority=/k8s/kubernetes/cfg/ssl/ca.pem --embed-certs=true --server=https://127.0.0.1:16443 --kubeconfig=admin.kubeconfig $ kubectl config set-credentials admin --client-certificate=/k8s/kubernetes/cfg/ssl/admin.pem --client-key=/k8s/kubernetes/cfg/ssl/admin-key.pem --embed-certs=true --kubeconfig=admin.kubeconfig $ kubectl config set-context default --cluster=kubernetes --user=admin --kubeconfig=admin.kubeconfig $ kubectl config use-context default --kubeconfig=admin.kubeconfig $ kubectl config set-cluster kubernetes --certificate-authority=/k8s/kubernetes/cfg/ssl/ca.pem --embed-certs=true --server=https://127.0.0.1:16443 --kubeconfig=kube-controller-manager.kubeconfig $ kubectl config set-credentials system:kube-controller-manager --client-certificate=/k8s/kubernetes/cfg/ssl/admin.pem --client-key=/k8s/kubernetes/cfg/ssl/admin-key.pem --embed-certs=true --kubeconfig=kube-controller-manager.kubeconfig $ kubectl config set-context default --cluster=kubernetes --user=system:kube-controller-manager --kubeconfig=kube-controller-manager.kubeconfig $ kubectl config use-context default --kubeconfig=kube-controller-manager.kubeconfig $ kubectl config set-cluster kubernetes --certificate-authority=/k8s/kubernetes/cfg/ssl/ca.pem --embed-certs=true --server=https://127.0.0.1:16443 --kubeconfig=kube-scheduler.kubeconfig $ kubectl config set-credentials system:kube-scheduler --client-certificate=/k8s/kubernetes/cfg/ssl/admin.pem --client-key=/k8s/kubernetes/cfg/ssl/admin-key.pem --embed-certs=true --kubeconfig=kube-scheduler.kubeconfig $ kubectl config set-context default --cluster=kubernetes --user=system:kube-scheduler --kubeconfig=kube-scheduler.kubeconfig $ kubectl config use-context default --kubeconfig=kube-scheduler.kubeconfig $ cp admin.kubeconfig kube-controller-manager.kubeconfig kube-scheduler.kubeconfig /k8s/kubernetes/cfg/kubeconfig/ $ mkdir -p ~/.kube && cp admin.kubeconfig ~/.kube/config $ scp -r /k8s/kubernetes/cfg/kubeconfig root@centos10-07:/k8s/kubernetes/cfg/ $ scp -r /k8s/kubernetes/cfg/kubeconfig root@centos10-08:/k8s/kubernetes/cfg/
阶段 3.4:对号入座,注入各自的 ApiServer 启动参数(绑定各台机器自己的物理网卡 IP,必须各自独立执行!)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 $ cat <<EOF | tee /k8s/kubernetes/cfg/kube-apiserver.conf KUBE_APISERVER_OPTS="--v=2 \\ --advertise-address=192.168.1.7 \\ --bind-address=192.168.1.7 \\ --secure-port=6443 \\ --service-cluster-ip-range=10.96.0.0/16 \\ --service-node-port-range=30000-32767 \\ --etcd-servers=https://192.168.1.7:2379,https://192.168.1.6:2379,https://192.168.1.14:2379 \\ --etcd-cafile=/k8s/kubernetes/cfg/ssl/ca.pem \\ --etcd-certfile=/k8s/kubernetes/cfg/ssl/etcd.pem \\ --etcd-keyfile=/k8s/kubernetes/cfg/ssl/etcd-key.pem \\ --client-ca-file=/k8s/kubernetes/cfg/ssl/ca.pem \\ --tls-cert-file=/k8s/kubernetes/cfg/ssl/kubernetes.pem \\ --tls-private-key-file=/k8s/kubernetes/cfg/ssl/kubernetes-key.pem \\ --service-account-key-file=/k8s/kubernetes/cfg/ssl/ca-key.pem \\ --service-account-signing-key-file=/k8s/kubernetes/cfg/ssl/ca-key.pem \\ --service-account-issuer=https://kubernetes.default.svc.cluster.local \\ --kubelet-client-certificate=/k8s/kubernetes/cfg/ssl/kubernetes.pem \\ --kubelet-client-key=/k8s/kubernetes/cfg/ssl/kubernetes-key.pem \\ --anonymous-auth=false \\ --authorization-mode=Node,RBAC \\ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota \\ --allow-privileged=true" EOF $ cat <<EOF | tee /k8s/kubernetes/cfg/kube-apiserver.conf KUBE_APISERVER_OPTS="--v=2 \\ --advertise-address=192.168.1.6 \\ --bind-address=192.168.1.6 \\ --secure-port=6443 \\ --service-cluster-ip-range=10.96.0.0/16 \\ --service-node-port-range=30000-32767 \\ --etcd-servers=https://192.168.1.7:2379,https://192.168.1.6:2379,https://192.168.1.14:2379 \\ --etcd-cafile=/k8s/kubernetes/cfg/ssl/ca.pem \\ --etcd-certfile=/k8s/kubernetes/cfg/ssl/etcd.pem \\ --etcd-keyfile=/k8s/kubernetes/cfg/ssl/etcd-key.pem \\ --client-ca-file=/k8s/kubernetes/cfg/ssl/ca.pem \\ --tls-cert-file=/k8s/kubernetes/cfg/ssl/kubernetes.pem \\ --tls-private-key-file=/k8s/kubernetes/cfg/ssl/kubernetes-key.pem \\ --service-account-key-file=/k8s/kubernetes/cfg/ssl/ca-key.pem \\ --service-account-signing-key-file=/k8s/kubernetes/cfg/ssl/ca-key.pem \\ --service-account-issuer=https://kubernetes.default.svc.cluster.local \\ --kubelet-client-certificate=/k8s/kubernetes/cfg/ssl/kubernetes.pem \\ --kubelet-client-key=/k8s/kubernetes/cfg/ssl/kubernetes-key.pem \\ --anonymous-auth=false \\ --authorization-mode=Node,RBAC \\ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota \\ --allow-privileged=true" EOF $ cat <<EOF | tee /k8s/kubernetes/cfg/kube-apiserver.conf KUBE_APISERVER_OPTS="--v=2 \\ --advertise-address=192.168.1.14 \\ --bind-address=192.168.1.14 \\ --secure-port=6443 \\ --service-cluster-ip-range=10.96.0.0/16 \\ --service-node-port-range=30000-32767 \\ --etcd-servers=https://192.168.1.7:2379,https://192.168.1.6:2379,https://192.168.1.14:2379 \\ --etcd-cafile=/k8s/kubernetes/cfg/ssl/ca.pem \\ --etcd-certfile=/k8s/kubernetes/cfg/ssl/etcd.pem \\ --etcd-keyfile=/k8s/kubernetes/cfg/ssl/etcd-key.pem \\ --client-ca-file=/k8s/kubernetes/cfg/ssl/ca.pem \\ --tls-cert-file=/k8s/kubernetes/cfg/ssl/kubernetes.pem \\ --tls-private-key-file=/k8s/kubernetes/cfg/ssl/kubernetes-key.pem \\ --service-account-key-file=/k8s/kubernetes/cfg/ssl/ca-key.pem \\ --service-account-signing-key-file=/k8s/kubernetes/cfg/ssl/ca-key.pem \\ --service-account-issuer=https://kubernetes.default.svc.cluster.local \\ --kubelet-client-certificate=/k8s/kubernetes/cfg/ssl/kubernetes.pem \\ --kubelet-client-key=/k8s/kubernetes/cfg/ssl/kubernetes-key.pem \\ --anonymous-auth=false \\ --authorization-mode=Node,RBAC \\ --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota \\ --allow-privileged=true" EOF
阶段 3.5:手写控制器、调度器及 Systemd 卡片(3台 Master 同步流)。开启 3 台 Master 的同步窗口,统一扔入通用启动参数和系统托管服务卡片。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 mkdir -p /var/log/kubernetes$ cat <<EOF | tee /k8s/kubernetes/cfg/kube-controller-manager.conf KUBE_CONTROLLER_MANAGER_OPTS="--v=2 \\ --kubeconfig=/k8s/kubernetes/cfg/kubeconfig/kube-controller-manager.kubeconfig \\ --bind-address=127.0.0.1 \\ --allocate-node-cidrs=true \\ --cluster-cidr=10.244.0.0/16 \\ --service-cluster-ip-range=10.96.0.0/16 \\ --cluster-signing-cert-file=/k8s/kubernetes/cfg/ssl/ca.pem \\ --cluster-signing-key-file=/k8s/kubernetes/cfg/ssl/ca-key.pem \\ --root-ca-file=/k8s/kubernetes/cfg/ssl/ca.pem \\ --service-account-private-key-file=/k8s/kubernetes/cfg/ssl/ca-key.pem \\ --leader-elect=true" EOF $ cat <<EOF | tee /k8s/kubernetes/cfg/kube-scheduler.conf KUBE_SCHEDULER_OPTS="--v=2 \\ --kubeconfig=/k8s/kubernetes/cfg/kubeconfig/kube-scheduler.kubeconfig \\ --bind-address=127.0.0.1 \\ --leader-elect=true" EOF $ cat <<EOF | tee /usr/lib/systemd/system/kube-apiserver.service [Unit] Description=Kubernetes API Server Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] EnvironmentFile=/k8s/kubernetes/cfg/kube-apiserver.conf ExecStart=/k8s/kubernetes/bin/kube-apiserver \$KUBE_APISERVER_OPTS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF $ cat <<EOF | tee /usr/lib/systemd/system/kube-controller-manager.service [Unit] Description=Kubernetes Controller Manager Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] EnvironmentFile=/k8s/kubernetes/cfg/kube-controller-manager.conf ExecStart=/k8s/kubernetes/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF $ cat <<EOF | tee /usr/lib/systemd/system/kube-scheduler.service [Unit] Description=Kubernetes Scheduler Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] EnvironmentFile=/k8s/kubernetes/cfg/kube-scheduler.conf ExecStart=/k8s/kubernetes/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF
阶段 3.6:三星合闸!见证 K8s 大脑彻底苏醒(3台 Master 同步流)
1 2 3 4 5 6 7 8 $ systemctl daemon-reload $ systemctl start kube-apiserver kube-controller-manager kube-scheduler $ systemctl enable kube-apiserver kube-controller-manager kube-scheduler
阶段 3.7:验证
通过 HAProxy 反向对账盘查。现在回到 centos10-06 的独立控制台里,直接敲击最高鉴权指令:
如果出现错误,那么改完之后,执行以下命令进行重启修复:
1 2 3 4 5 6 7 systemctl reset-failed kube-apiserver kube-controller-manager systemctl daemon-reload systemctl restart kube-apiserver kube-controller-manager kube-scheduler systemctl restart haproxy
如果正常启动,那么预期输出如下:
1 2 3 4 5 6 $ kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR controller-manager Healthy ok scheduler Healthy ok etcd-0 Healthy ok
安装 Containerd 安装 Containerd 容器运行时。全部 5 台机器统一执行以下命令,把 Docker 剥离后最正宗的 K8s CRI 运行时焊死在系统底层:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 $ yum install -y yum-utils device-mapper-persistent-data lvm2 $ yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo $ yum makecache $ yum install -y containerd.io $ mkdir -p /etc/containerd $ containerd config default | tee /etc/containerd/config.toml $ sed -i 's|registry.k8s.io/pause:3.10.1|registry.aliyuncs.com/google_containers/pause:3.10.1|g' /etc/containerd/config.toml $ sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml $ systemctl daemon-reload && systemctl restart containerd && systemctl enable containerd $ systemctl daemon-reload && systemctl restart containerd $ ctr version $ systemctl status containerd
kubelet 和 kube-proxy 回到 centos10-06 的独立控制台,把解压出来的 Worker 节点触角二进制组件和凭证隔空送往其余 4 台机器:
1 2 3 4 5 6 7 8 9 10 $ cp /root/kubernetes/server/bin/kubelet /root/kubernetes/server/bin/kube-proxy /k8s/kubernetes/bin/ $ zcall mkdir -p /k8s/kubernetes/bin/ $ zcall mkdir -p /k8s/kubernetes/cfg/ssl/ $ for h in centos10-07 centos10-08 centos10-09 centos10-10; do scp /k8s/kubernetes/bin/kubelet /k8s/kubernetes/bin/kube-proxy root@$h :/k8s/kubernetes/bin/ scp /k8s/kubernetes/cfg/ssl/*.pem root@$h :/k8s/kubernetes/cfg/ssl/ done
我们要给 5 台机器的 kubelet 和 kube-proxy 签发去觐见 HAProxy 的特权公文包。请继续在 centos10-06 执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 cd /k8s/v1.28.2/workkubectl config set-cluster kubernetes --certificate-authority=/k8s/kubernetes/cfg/ssl/ca.pem --embed-certs=true --server=https://127.0.0.1:16443 --kubeconfig=kubelet.kubeconfig kubectl config set-credentials system:node --client-certificate=/k8s/kubernetes/cfg/ssl/admin.pem --client-key=/k8s/kubernetes/cfg/ssl/admin-key.pem --embed-certs=true --kubeconfig=kubelet.kubeconfig kubectl config set-context default --cluster=kubernetes --user=system:node --kubeconfig=kubelet.kubeconfig kubectl config use-context default --kubeconfig=kubelet.kubeconfig kubectl config set-cluster kubernetes --certificate-authority=/k8s/kubernetes/cfg/ssl/ca.pem --embed-certs=true --server=https://127.0.0.1:16443 --kubeconfig=kube-proxy.kubeconfig kubectl config set-credentials system:kube-proxy --client-certificate=/k8s/kubernetes/cfg/ssl/kube-proxy.pem --client-key=/k8s/kubernetes/cfg/ssl/kube-proxy-key.pem --embed-certs=true --kubeconfig=kube-proxy.kubeconfig kubectl config set-context default --cluster=kubernetes --user=system:kube-proxy --kubeconfig=kube-proxy.kubeconfig kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig cp kubelet.kubeconfig kube-proxy.kubeconfig /k8s/kubernetes/cfg/kubeconfig/for h in centos10-07 centos10-08 centos10-09 centos10-10; do ssh root@$h "mkdir -p /k8s/kubernetes/cfg/kubeconfig" scp /k8s/kubernetes/cfg/kubeconfig/*.kubeconfig root@$h :/k8s/kubernetes/cfg/kubeconfig/ done
编写 5 台机器各自独有的 Kubelet 配置文件。因为每台机器的 IP 和主机名不同,请分别点入各自的终端执行对应的命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 cat <<EOF | tee /k8s/kubernetes/cfg/kubelet.conf KUBELET_OPTS="--v=2 \\ --hostname-override=centos10-06 \\ --kubeconfig=/k8s/kubernetes/cfg/kubeconfig/kubelet.kubeconfig \\ --config=/k8s/kubernetes/cfg/kubelet-config.yml \\ --container-runtime-endpoint=unix:///run/containerd/containerd.sock" EOF cat <<EOF | tee /k8s/kubernetes/cfg/kubelet.conf KUBELET_OPTS="--v=2 \\ --hostname-override=centos10-07 \\ --kubeconfig=/k8s/kubernetes/cfg/kubeconfig/kubelet.kubeconfig \\ --config=/k8s/kubernetes/cfg/kubelet-config.yml \\ --container-runtime-endpoint=unix:///run/containerd/containerd.sock" EOF cat <<EOF | tee /k8s/kubernetes/cfg/kubelet.conf KUBELET_OPTS="--v=2 \\ --hostname-override=centos10-08 \\ --kubeconfig=/k8s/kubernetes/cfg/kubeconfig/kubelet.kubeconfig \\ --config=/k8s/kubernetes/cfg/kubelet-config.yml \\ --container-runtime-endpoint=unix:///run/containerd/containerd.sock" EOF cat <<EOF | tee /k8s/kubernetes/cfg/kubelet.conf KUBELET_OPTS="--v=2 \\ --hostname-override=centos10-09 \\ --kubeconfig=/k8s/kubernetes/cfg/kubeconfig/kubelet.kubeconfig \\ --config=/k8s/kubernetes/cfg/kubelet-config.yml \\ --container-runtime-endpoint=unix:///run/containerd/containerd.sock" EOF cat <<EOF | tee /k8s/kubernetes/cfg/kubelet.conf KUBELET_OPTS="--v=2 \\ --hostname-override=centos10-10 \\ --kubeconfig=/k8s/kubernetes/cfg/kubeconfig/kubelet.kubeconfig \\ --config=/k8s/kubernetes/cfg/kubelet-config.yml \\ --container-runtime-endpoint=unix:///run/containerd/containerd.sock" EOF
注入通用的高级 Cgroup 控制策略。请开启 5 台机器的同步窗口,注入组件的核心 yml 运作参数及 Systemd 系统卡片:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 cat <<EOF | tee /k8s/kubernetes/cfg/kubelet-config.yml kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 address: 0.0.0.0 port: 10250 readOnlyPort: 10255 cgroupDriver: systemd clusterDNS: - 10.96.0.10 clusterDomain: cluster.local failSwapOn: false authentication: anonymous: enabled: false webhook: cacheTTL: 2m0s enabled: true x509: clientCAFile: /k8s/kubernetes/cfg/ssl/ca.pem authorization: mode: Webhook webhook: cacheAuthorizedTTL: 5m0s cacheUnauthorizedTTL: 30s EOF cat <<EOF | tee /k8s/kubernetes/cfg/kube-proxy.conf KUBE_PROXY_OPTS="--v=2 \\ --config=/k8s/kubernetes/cfg/kube-proxy-config.yml" EOF cat <<EOF | tee /k8s/kubernetes/cfg/kube-proxy-config.yml kind: KubeProxyConfiguration apiVersion: kubeproxy.config.k8s.io/v1alpha1 bindAddress: 0.0.0.0 metricsBindAddress: 0.0.0.0:10249 clientConnection: kubeconfig: /k8s/kubernetes/cfg/kubeconfig/kube-proxy.kubeconfig mode: ipvs clusterCIDR: 10.244.0.0/16 EOF cat <<EOF | tee /usr/lib/systemd/system/kubelet.service [Unit] Description=Kubernetes Kubelet Documentation=https://github.com/kubernetes/kubernetes After=containerd.service Requires=containerd.service [Service] EnvironmentFile=/k8s/kubernetes/cfg/kubelet.conf ExecStart=/k8s/kubernetes/bin/kubelet \$KUBELET_OPTS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF cat <<EOF | tee /usr/lib/systemd/system/kube-proxy.service [Unit] Description=Kubernetes Kube-Proxy Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] EnvironmentFile=/k8s/kubernetes/cfg/kube-proxy.conf ExecStart=/k8s/kubernetes/bin/kube-proxy \$KUBE_PROXY_OPTS Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target EOF
纯 Worker 节点补全 HAProxy 本地门卫(在 centos10-09 和 centos10-10 上执行)。
因为 centos10-09 和 centos10-10 作为纯 Worker 节点,其本地的 kubelet 也会去找 127.0.0.1:16443。 所以请把阶段 3.1 编写好的 HAProxy 复制并拉起在这两台机器上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [centos10-09 节点] kubelet ---> (访问本地) 127.0.0.1:6443 (本地 HAProxy) │ ┌───────────────────────┼───────────────────────┐ (跨网络分发) ▼ ▼ ▼ [centos10-06 APIServer] [centos10-07 APIServer] [centos10-08 APIServer]
1 2 3 4 5 6 7 8 yum install -y haproxy scp root@centos10-06:/etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg systemctl daemon-reload && systemctl start haproxy && systemctl enable haproxy netstat -lntp | grep 16443
五台机器全量合闸!开始迎集群正式诞生!
1 2 3 4 5 6 7 8 9 10 11 12 systemctl daemon-reload systemctl restart kubelet kube-proxy systemctl enable kubelet kube-proxy $ kubectl get nodes NAME STATUS ROLES AGE VERSION centos10-06 Ready <none> 30s v1.28.2 centos10-07 Ready <none> 28s v1.28.2 centos10-08 Ready <none> 25s v1.28.2 centos10-09 Ready <none> 22s v1.28.2 centos10-10 Ready <none> 20s v1.28.2
但是很遗憾,状态全都是 NotReady!原因是 Kubernetes 的核心设计是分层治理。现在各节点的骨架(Containerd + Kubelet)虽然对接成功了,但集群的网络大动脉还没有打通。各个节点之间现在还不知道该怎么给 Pod 分配容器 IP,也不知道怎么跨机器进行通信。我们可以通过一个硬核命令来证实这个猜测。在 centos10-06 上随便挑一台机器死磕倒查:
1 kubectl describe node centos10-06 | grep -i cni
你绝对会看到类似这样的一句话:network plugin is not ready: cni config uninitialized(CNI 网络插件未初始化)。为了让集群从 NotReady 瞬间蜕变为全绿的 Ready,我们必须平铺大名鼎鼎的 Calico 三层路由网络拓扑插件。请在 centos10-06 的独立窗口执行以下一连串命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 cd /k8s/v1.28.2/workcurl -O https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/calico.yaml sed -i 's/# - name: CALICO_IPV4POOL_CIDR/- name: CALICO_IPV4POOL_CIDR/g' calico.yaml sed -i 's/# value: "192.168.0.0\/16"/ value: "10.244.0.0\/16"/g' calico.yaml sed -i 's|docker.io/calico/|docker.m.daocloud.io/calico/|g' calico.yaml kubectl apply -f calico.yaml kubectl delete pods -n kube-system -l k8s-app=calico-node --force --grace-period=0 kubectl delete pods -n kube-system -l k8s-app=calico-kube-controllers --force --grace-period=0 kubectl delete pods -n kube-system --all --force --grace-period=0 kubectl get pods -n kube-system -w kubectl get nodes NAME STATUS ROLES AGE VERSION centos10-06 Ready <none> 33m v1.28.2 centos10-07 Ready <none> 33m v1.28.2 centos10-08 Ready <none> 33m v1.28.2 centos10-09 Ready <none> 33m v1.28.2 centos10-10 Ready <none> 33m v1.28.2 kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR etcd-0 Healthy ok controller-manager Healthy ok scheduler Healthy ok
部署一个测试应用 直接往这个刚出炉的纯血二进制集群里扔一个 Nginx 压压惊,顺便肉眼检验一下跨机器的网络路由是否真正顺畅。在 centos10-06 的独立控制台执行:
1 2 3 4 5 kubectl create deployment nginx-test --image=docker.m.daocloud.io/library/nginx:alpine --replicas=3 kubectl get pods -o wide -w
看到 3 个 Nginx 稳稳拿到 10.244.x.x 的 Pod 内网 IP 跑起来后,按 Ctrl + C 退出。然后你可以直接在任意一台虚拟机上人肉 curl,只要能吐出 Welcome to nginx,说明我们的集群已经成功部署完成!
1 2 3 4 5 6 7 8 9 10 11 12 $ kubectl get pods -o wide -w NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-test-858cd7cc5b-jmfr2 1/1 Running 0 4m47s 10.244.73.193 centos10-09 <none> <none> nginx-test-858cd7cc5b-l6tlw 1/1 Running 0 4m47s 10.244.48.129 centos10-07 <none> <none> nginx-test-858cd7cc5b-zntqk 1/1 Running 0 4m47s 10.244.73.65 centos10-06 <none> <none> $ curl 10.244.73.193 <!DOCTYPE html> <html> <head > <title>Welcome to nginx!</title> ...
彻底卸载掉刚才安装的 nginx。当你删掉了 deployment,Kubernetes 会自动向底层 5 台机器的 kubelet 发送销毁密令。各节点的 Containerd 会瞬间对那 3 个 Nginx 容器执行物理下线并清空网络占位,整个过程在几秒钟内无痕完成
1 2 3 4 5 6 7 8 9 10 11 12 13 $ kubectl get pods,deployments NAME READY STATUS RESTARTS AGE pod/nginx-test-858cd7cc5b-jmfr2 1/1 Running 0 11m pod/nginx-test-858cd7cc5b-l6tlw 1/1 Running 0 11m pod/nginx-test-858cd7cc5b-zntqk 1/1 Run $ kubectl delete deployment nginx-test $ kubectl get pods,deployments No resources found in default namespace.
集群的优化 安装 CoreDNS CoreDNS 是 K8s 内部服务的“民政局”(Service 域名解析),当未来我们在集群里创建一个叫 mysql 的 Service(服务)时,CoreDNS 会自动在集群内部注册一条解析 “mysql.default.svc.cluster.local ===> 指向真实的 Service VIP”,如果没有 CoreDNS,我们的业务 Pod 想访问数据库,只能在代码里硬编码写死 10.96.x.x 这样的 Service IP。一旦重构或迁移,整个代码就会全面崩溃。装了 CoreDNS,代码里直接无脑写 http://mysql 就能一枪穿透!
如果用 kubeadm 一键搭建的集群,它会在后台默默帮你把 CoreDNS 以 Pod 的形式直接塞进 kube-system 里。但我们现在走的是纯手工二进制筑基,K8s 官方二进制包只给了你最骨干的“三大件”(Apiserver, Controller, Scheduler)。像网络插件(Calico)和域名解析(CoreDNS),都属于集群附随生态插件(Add-on),官方把控制权完全交给了你,必须由你人肉宣读公文去激活它。
既然大动脉已经通电,我们直接在总指挥部 centos10-06 上把 CoreDNS 焊进集群。
第一步:下载并修剪官方清单
1 2 3 cd /k8s/v1.28.2/workcurl -O https://raw.githubusercontent.com/coredns/deployment/master/kubernetes/coredns.yaml.sed
官方提供的是一个 .sed 模板,我们需要把它具象化。通常二进制集群中,我们会把全局的集群 DNS 守护 IP 定死在 10.96.0.10(必须跟之前配置 kubelet 时,配置文件里写的 clusterDNS: [“10.96.0.10”] 完全对齐)。由于更改的地方较多,我打算直接手撕一个 coredns.yaml,输入 “vim coredns.yaml”,结合 :set paste 粘贴进以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 apiVersion: v1 kind: ServiceAccount metadata: name: coredns namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: kubernetes.io/bootstrapping: rbac-defaults name: system:coredns rules: - apiGroups: - "" resources: - endpoints - services - pods - namespaces verbs: - list - watch - apiGroups: - discovery.k8s.io resources: - endpointslices verbs: - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:coredns roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:coredns subjects: - kind: ServiceAccount name: coredns namespace: kube-system --- apiVersion: v1 kind: ConfigMap metadata: name: coredns namespace: kube-system data: Corefile: | .:53 { errors health { lameduck 5s } ready kubernetes cluster.local in-addr.arpa ip6.arpa { fallthrough in-addr.arpa ip6.arpa } prometheus :9153 forward . /etc/resolv.conf { max_concurrent 1000 } cache 30 loop reload loadbalance } --- apiVersion: apps/v1 kind: Deployment metadata: name: coredns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/name: "CoreDNS" app.kubernetes.io/name: coredns spec: replicas: 2 strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 selector: matchLabels: k8s-app: kube-dns app.kubernetes.io/name: coredns template: metadata: labels: k8s-app: kube-dns app.kubernetes.io/name: coredns spec: priorityClassName: system-cluster-critical serviceAccountName: coredns tolerations: - key: "CriticalAddonsOnly" operator: "Exists" nodeSelector: kubernetes.io/os: linux affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: k8s-app operator: In values: ["kube-dns" ] topologyKey: kubernetes.io/hostname containers: - name: coredns image: docker.m.daocloud.io/coredns/coredns:1.9.4 imagePullPolicy: IfNotPresent resources: limits: memory: 170Mi requests: cpu: 100m memory: 70Mi args: [ "-conf" , "/etc/coredns/Corefile" ] volumeMounts: - name: config-volume mountPath: /etc/coredns readOnly: true ports: - containerPort: 53 name: dns protocol: UDP - containerPort: 53 name: dns-tcp protocol: TCP - containerPort: 9153 name: metrics protocol: TCP securityContext: allowPrivilegeEscalation: false capabilities: add: - NET_BIND_SERVICE drop: - all readOnlyRootFilesystem: true livenessProbe: httpGet: path: /health port: 8080 scheme: HTTP initialDelaySeconds: 60 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 5 readinessProbe: httpGet: path: /ready port: 8181 scheme: HTTP dnsPolicy: Default volumes: - name: config-volume configMap: name: coredns items: - key: Corefile path: Corefile --- apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system annotations: prometheus.io/port: "9153" prometheus.io/scrape: "true" labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" kubernetes.io/name: "CoreDNS" app.kubernetes.io/name: coredns spec: selector: k8s-app: kube-dns app.kubernetes.io/name: coredns clusterIP: 10.96 .0 .10 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP - name: metrics port: 9153 protocol: TCP
我把 replicas(副本数)显式指定为了 2。并且利用模板中自带的 podAntiAffinity(反亲和性)规则,K8s 会自动把这两个 CoreDNS Pod 分散部署在两台不同的物理机上,做到高可用域名解析,任何一台虚拟机挂了都不影响集群解析。
第二步:将 CoreDNS 注入大本营
1 2 3 4 5 kubectl apply -f coredns.yaml kubectl get pods -n kube-system -l k8s-app=kube-dns -w
等待 10 秒左右,直到看到 2 个 coredns 副本的状态齐刷刷定格在 Running (1/1),就说明整个集群的灵魂核心——域名解析中枢,已经完美在k8s集群中筑基成功了。
第三步:进行测试
1 2 3 4 5 6 7 8 9 10 11 $ kubectl create clusterrolebinding kubernetes-kubelet-admin \ --clusterrole=system:kubelet-api-admin \ --user=kubernetes $ kubectl run net-test --image=docker.m.daocloud.io/library/busybox:1.28 --rm -it --restart=Never -- nslookup kubernetes.default If you don't see a command prompt, try pressing enter. Name: kubernetes.default Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local pod "net-test" deleted
安装 Metrics-server Metrics-server 是 Kubernetes 集群核心资源监控数据的唯一官方聚合器。它负责每隔十几秒向全网 5 台机器的 kubelet 挨个盘问:“你现在吃了多少 CPU?还剩多少内存?” 然后把这些账本汇聚到内存中。
没安装时:你想看哪台虚拟机快爆仓了,必须肉眼去瞅 kubectl describe nodes 里密密麻麻的百分比。如果你敲 kubectl top node 或 kubectl top pod -A,系统会直接无情拒绝你:error: Metrics API not available。
安装之后:直接激活硬核 Linux top 体验!如果你未来希望你的业务 Pod 在高并发时(比如 CPU 超过 80%)自动从 3 副本变成 10 副本,底层必须依赖 Metrics-server 提供的数据源。
我们开始进行安装。在 centos10-06 上直接执行以下步骤。
第一步:直接创建完全体 metrics-server.yaml
1 2 cd /k8s/v1.28.2/workvim metrics-server.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 apiVersion: v1 kind: Namespace metadata: name: kubernetes-dashboard --- apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server kubernetes.io/bootstrapping: rbac-defaults name: system:aggregated-metrics-reader rules: - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server name: system:metrics-server rules: - apiGroups: - "" resources: - nodes/metrics verbs: - get - apiGroups: - "" resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: v1 kind: Service metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: ports: - name: https port: 443 protocol: TCP targetPort: main-port selector: k8s-app: metrics-server --- apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: selector: matchLabels: k8s-app: metrics-server strategy: rollingUpdate: maxUnavailable: 1 type: RollingUpdate template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --secure-port=10250 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port - --metric-resolution=15s - --kubelet-insecure-tls image: docker.m.daocloud.io/sig-storage/metrics-server:v0.7.1 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 name: metrics-server ports: - containerPort: 10250 name: main-port protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS periodSeconds: 10 resources: limits: memory: 300Mi requests: cpu: 100m memory: 100Mi securityContext: allowPrivilegeEscalation: false capabilities: drop: - ALL readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - mountPath: /tmp name: tmp-dir nodeSelector: kubernetes.io/os: linux priorityClassName: system-cluster-critical serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: k8s-app: metrics-server name: v1beta1.metrics.k8s.io spec: group: metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: metrics-server namespace: kube-system version: v1beta1 versionPriority: 100
第二步:合闸通电并网
1 2 3 4 5 6 7 kubectl apply -f metrics-server.yaml kubectl get pods -n kube-system -l k8s-app=metrics-server -w metrics-server-587f58d5cb-tcfk9 0/1 ErrImagePull 0 49s metrics-server-587f58d5cb-tcfk9 0/1 ImagePullBackOff 0 53s metrics-server-587f58d5cb-tcfk9 0/1 ErrImagePull 0 66s metrics-server-587f58d5cb-tcfk9 0/1 ImagePullBackOff 0 77s
结果出现了 ErrImagePull 和 ImagePullBackOff,这说明计算节点在尝试拉取镜像时遇到了网络阻碍。看看这个可怜的 Pod 到底被分配到了哪台虚拟机上:
1 2 3 4 $ kubectl get pods -n kube-system -l k8s-app=metrics-server -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES metrics-server-587f58d5cb-tcfk9 0/1 ImagePullBackOff 0 4m45s 10.244.48.130 centos10-07 <none> <none>
然后我们切到 centos10-07 这台机器上:
1 2 3 4 5 6 7 $ vim /etc/resolv.conf nameserver 223.5.5.5 nameserver 114.114.114.114 $ /usr/bin/ctr -n k8s.io image pull registry.aliyuncs.com/google_containers/metrics-server:v0.7.1
只要 07 节点本地有了镜像,剩下的就是走 K8s 的官方宣告流程了。切回 centos10-06(主控节点)的工作目录下,魔改我们的清单,把原本那个翻车的地址强行修正为阿里云地址:
1 2 3 image: registry.aliyuncs.com/google_containers/metrics-server:v0.7.1 imagePullPolicy: IfNotPresent
然后,直接给集群下达终极合闸令:
1 2 3 4 5 6 7 8 9 10 11 12 kubectl apply -f metrics-server.yaml kubectl get pods -n kube-system -l k8s-app=metrics-server -w NAME READY STATUS RESTARTS AGE metrics-server-6b8b7c46b5-rdtgz 0/1 ContainerCreating 0 17s metrics-server-6b8b7c46b5-rdtgz 0/1 Running 0 27s metrics-server-6b8b7c46b5-rdtgz 0/1 Error 0 66s metrics-server-6b8b7c46b5-rdtgz 0/1 Running 1 (3s ago) 68s metrics-server-6b8b7c46b5-rdtgz 0/1 Error 1 (39s ago) 104s
但是,看到后面陷入了 Error -> CrashLoopBackOff 的循环,这说明我们进入了安装 Metrics-Server 的第二个经典战役——程序内部闪退。镜像既然没问题,闪退多半是因为 Metrics-Server 进程在启动时,发现有些参数或集群环境对不上,导致它自己抛出异常自杀了。
1 2 3 4 5 6 7 kubectl logs -n kube-system metrics-server-6b8b7c46b5-rdtgz --tail =50 dial tcp xxx:10250: i/o timeout / context deadline exceeded err="Get \"https://192.168.1.7:10250/metrics/resource\": context deadline exceeded" node="centos10-06" err="Get \"https://192.168.1.6:10250/metrics/resource\": dial tcp 192.168.1.6:10250: i/o timeout" node="centos10-07" ...
在二进制高可用集群中,发生这种跨机 10250 端口超时,100% 是以下两个暗桩在作祟。直接开始排查修复。
第一步:物理排查虚拟机防火墙(5台机器同步检查!)。CentOS 7/10 默认自带的 firewalld 会铁面无私地拦截一切未报备的端口入流量。
1 2 3 4 5 6 systemctl status firewalld systemctl stop firewalld systemctl disable firewalld
第二步:Kubelet 监听网卡死锁对账(重点排查!)
如果防火墙早已关闭,那问题一定出在 kubelet 的启动参数上。 请登录两台卡死最严重的物理机(比如 centos10-06 和 centos10-07),查看它们的 kubelet 进程到底把 10250 端口绑定在哪个网卡上了:
1 2 3 4 5 6 7 netstat -ntlp | grep 10250
做完以上的排查,在 06 执行我们发现 状态停留在 0/1 Running。好消息是容器再也没有因为网络超时而崩溃自杀,但 0/1 Running 意味着容器内的 Metrics-Server 主进程跑得好好的,但是它的就绪检查探针(Readiness Probe)依然被拦在门外。再结合刚才日志里疯狂刷屏的那句话:”kube-system/extension-apiserver-authentication failed with : missing content for CA bundle “client-ca::…”。Metrics-Server 在作为聚合 API(API Aggregation)并网时,需要向 K8s 大脑证明自己是内部合法的安全组件。而你的二进制高可用集群在配置 kube-apiserver 的启动参数时,少传了认证代理的前置安全证书账本。K8s 大脑不给它下发证书公钥,导致它的安全通道(/readyz)死活无法变成绿色健康状态。
1 2 3 $ kubectl get pods -n kube-system -l k8s-app=metrics-server -w NAME READY STATUS RESTARTS AGE metrics-server-6b8b7c46b5-rdtgz 0/1 Running 4 (23m ago) 27m
我们现在来签发 Metrics-Server 所需要的 front-proxy(前置安全代理)证书。
第一步:手写前置代理证书请求(CN 必须是固定死锁的)
在 centos10-06 终端直接复制运行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 cd /k8s/v1.28.2/workcat <<EOF | tee front-proxy-client-csr.json { "CN": "front-proxy-client", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "L": "Beijing", "O": "k8s", "OU": "system" } ] } EOF
第二步:动用 cfssl 印章,现场签署
1 2 3 4 5 6 7 8 9 10 11 12 $ cfssl gencert \ -ca=ca.pem \ -ca-key=ca-key.pem \ -config=ca-config.json \ -profile=kubernetes \ front-proxy-client-csr.json | cfssljson -bare front-proxy-client $ ls -l front-proxy-client* front-proxy-client.csr front-proxy-client-csr.json front-proxy-client-key.pem front-proxy-client.pem
第三步:把新弹药空投到 K8s 证书家园,以及其他主节点 Master 上
1 2 3 4 cp front-proxy-client.pem front-proxy-client-key.pem /k8s/kubernetes/cfg/ssl/scp /k8s/kubernetes/cfg/ssl/front-proxy-client.pem /k8s/kubernetes/cfg/ssl/front-proxy-client-key.pem root@centos10-07:/k8s/kubernetes/cfg/ssl/ scp /k8s/kubernetes/cfg/ssl/front-proxy-client.pem /k8s/kubernetes/cfg/ssl/front-proxy-client-key.pem root@centos10-08:/k8s/kubernetes/cfg/ssl/
第四步:给 kube-apiserver 开启第二道安检门,合闸通电。打开你的主脑启动配置文件(这里以最常见的系统服务文件为例),修改为如下内容(主节点 06 07 08 都要修改):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vim /usr/lib/systemd/system/kube-apiserver.service [Unit] Description=Kubernetes API Server Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] EnvironmentFile=/k8s/kubernetes/cfg/kube-apiserver.conf ExecStart=/k8s/kubernetes/bin/kube-apiserver $KUBE_APISERVER_OPTS \ --requestheader-client-ca-file=/k8s/kubernetes/cfg/ssl/ca.pem \ --requestheader-allowed-names=front-proxy-client \ --requestheader-extra-headers-prefix=X-Remote-Extra- \ --requestheader-group-headers=X-Remote-Group \ --requestheader-username-headers=X-Remote-User \ --proxy-client-cert-file=/k8s/kubernetes/cfg/ssl/front-proxy-client.pem \ --proxy-client-key-file=/k8s/kubernetes/cfg/ssl/front-proxy-client-key.pem Restart=on-failure LimitNOFILE=65536 [Install] WantedBy=multi-user.target scp /usr/lib/systemd/system/kube-apiserver.service root@centos10-07:/usr/lib/systemd/system/kube-apiserver.service scp /usr/lib/systemd/system/kube-apiserver.service root@centos10-08:/usr/lib/systemd/system/kube-apiserver.service
最后,为了避免网络冲突,请在 06 节点执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 $ kubectl edit deployment metrics-server -n kube-system spec: ... template: metadata: labels: k8s-app: metrics-server spec: hostNetwork: true containers: - name: metrics-server image: ... spec: template: spec: containers: - name: metrics-server args: - --kubelet-insecure-tls - --kubelet-preferred-address-types=InternalIP - --secure-port=10443 livenessProbe: failureThreshold: 3 httpGet: path: /livez port: 10443 scheme: HTTPS periodSeconds: 10 readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: 10443 scheme: HTTPS periodSeconds: 10 ports: - containerPort: 10443 name: https protocol: TCP
执行完毕之后。随后对主脑执行心脏复苏(在3台主节点执行):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 kubectl delete pod -n kube-system -l k8s-app=metrics-server kubectl delete pod -n kube-system -l k8s-app=calico-kube-controllers kubectl delete pod -n kube-system -l k8s-app=kube-dns kubectl delete pod -n kube-system -l k8s-app=calico-node kubectl delete apiservice v1beta1.metrics.k8s.io systemctl daemon-reload systemctl restart kube-apiserver kubectl get pods -n kube-system -w kubectl get nodes kubectl top node kubectl top pod -A
当中枢主脑带着全新参数复活,它就会跟 Metrics-Server 顺利对上暗号。那个苦苦等待了 20 分钟的 Pod,就会瞬间从 0/1 Running 跃升为 1/1 Ready!
K8s集群的关闭和重新启动 集群的关闭和断电 在直接拔掉机器的电源之前,为了防止 Etcd 数据断电损坏或写穿孔,请按照以下顺序安全关机:
关机命令 :poweroff 或 shutdown -h now。关计算节点 :先去关 centos10-09、centos10-10。关控制节点 :最后关 centos10-06、centos10-07、centos10-08。
下次开机的完美复活 下次把 5 台虚拟机全部开机后,严格按照以下 4 步重启集群即可(实际上我们已经设置了所有进程的开机自启动,一般下面步骤1~4是不用手动执行的,可以先查看相关进程是否正常已启动即可):
步骤 1:全量激活底层引擎(5 台机器同步执行)
开机后,第一件事是确保容器引擎和 Kubelet 正常通电。5 台机器同步执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 systemctl status firewalld systemctl stop firewalld systemctl disable firewalld systemctl start containerd systemctl start kubelet systemctl start kube-proxy systemctl status containerd kubelet
步骤 2:开启 HAProxy / Keepalived 负载均衡(高可用核心)
二进制集群是通过四层负载均衡反向代理 kube-apiserver 的。如果它们没起来,控制节点和计算节点都是瞎子。
请在所有控制节点(centos10-06、centos10-07、centos10-08)或者全部节点上执行:
1 2 3 4 5 6 7 systemctl start haproxy systemctl start keepalived ip addr show
步骤 3:唤醒 Master 核心大脑(控制节点执行)
现在,VIP 已经通了,我们要把 K8s 的核心三大件拉起来。在所有的控制节点上执行:
1 2 3 4 5 6 7 8 9 systemctl start etcd systemctl start kube-apiserver systemctl start kube-controller-manager systemctl start kube-scheduler kubectl get nodes
步骤 4:静候网络大动脉自动并网(无需手动 apply)
由于 Kubernetes 具有声明式持久化数据存储的特性,之前 kubectl apply -f calico.yaml 的账本已经死死刻在 Etcd 里面了。当 Containerd、Kubelet 和 Apiserver 全部通电完成通信后,Kubelet 会自动读取本地缓存,把 Calico 的全套容器自主拉起来,不需要你重新去 apply 那个 YAML。只需要静静等待观察:
1 2 3 4 5 kubectl get pods -n kube-system -w kubectl get nodes
标题:
K8s 集群的安装 - 使用二进制文件的方式进行进群的安装